Quick start
Installation
To gain high performance, LLamaSharp interacts with a native library compiled from c++, which is called backend. We provide backend packages for Windows, Linux and MAC with CPU, Cuda, Metal and OpenCL. You don't need to handle anything about c++ but just install the backend packages.
If no published backend match your device, please open an issue to let us know. If compiling c++ code is not difficult for you, you could also follow this guide to compile a backend and run LLamaSharp with it.
- Install LLamaSharp package on NuGet:
| PM> Install-Package LLamaSharp
|
-
Install one or more of these backends, or use self-compiled backend.
-
LLamaSharp.Backend.Cpu: Pure CPU for Windows & Linux & MAC. Metal (GPU) support for MAC.
LLamaSharp.Backend.Cuda11: CUDA11 for Windows & Linux.LLamaSharp.Backend.Cuda12: CUDA 12 for Windows & Linux.-
LLamaSharp.Backend.OpenCL: OpenCL for Windows & Linux.
-
(optional) For Microsoft semantic-kernel integration, install the LLamaSharp.semantic-kernel package.
- (optional) To enable RAG support, install the LLamaSharp.kernel-memory package (this package only supports
net6.0 or higher yet), which is based on Microsoft kernel-memory integration.
Model preparation
There are two popular format of model file of LLM now, which are PyTorch format (.pth) and Huggingface format (.bin). LLamaSharp uses GGUF format file, which could be converted from these two formats. To get GGUF file, there are two options:
-
Search model name + 'gguf' in Huggingface, you will find lots of model files that have already been converted to GGUF format. Please take care of the publishing time of them because some old ones could only work with old version of LLamaSharp.
-
Convert PyTorch or Huggingface format to GGUF format yourself. Please follow the instructions of this part of llama.cpp readme to convert them with the python scripts.
Generally, we recommend downloading models with quantization rather than fp16, because it significantly reduce the required memory size while only slightly impact on its generation quality.
Example of LLaMA chat session
Here is a simple example to chat with bot based on LLM in LLamaSharp. Please replace the model path with yours.
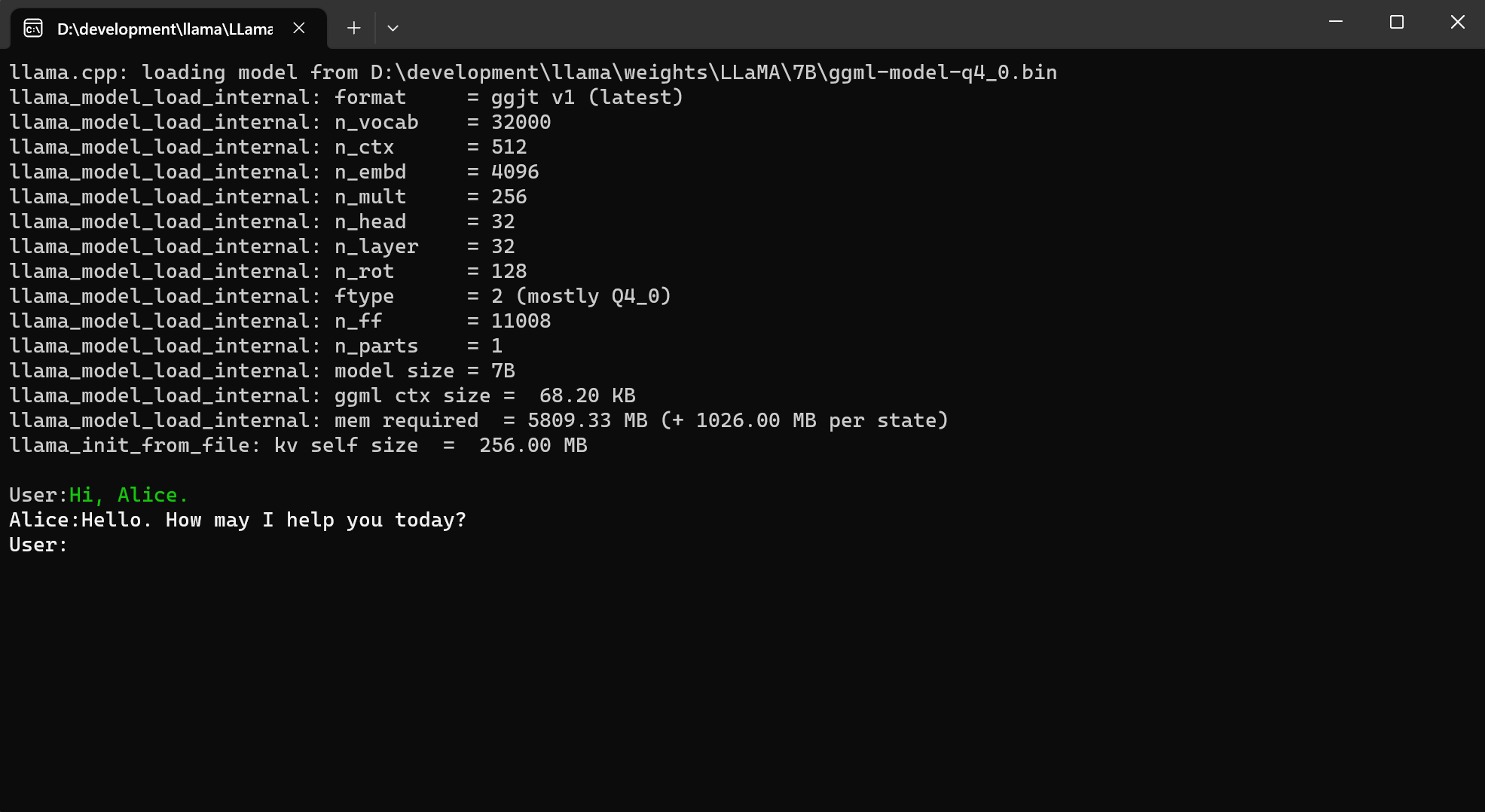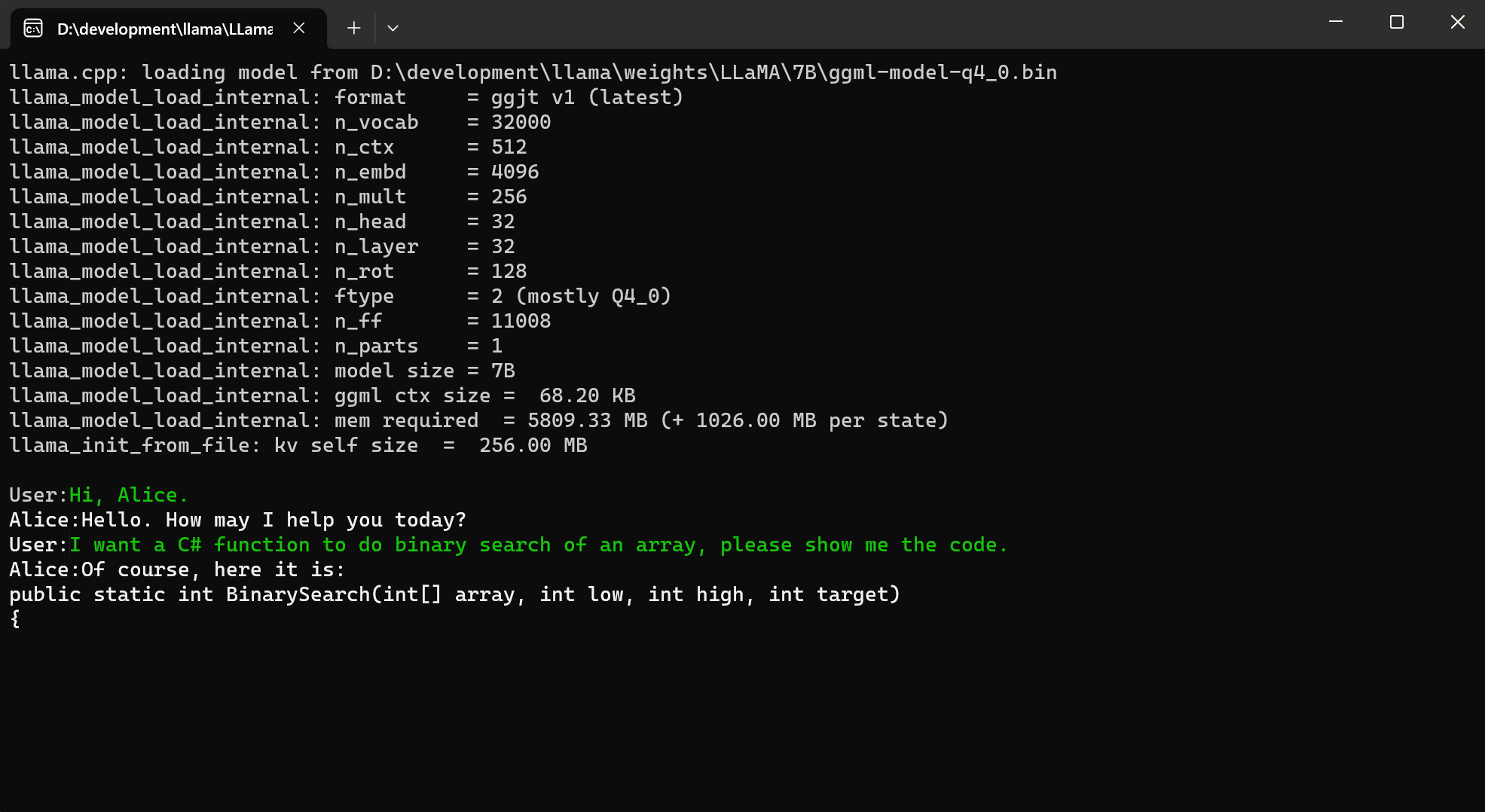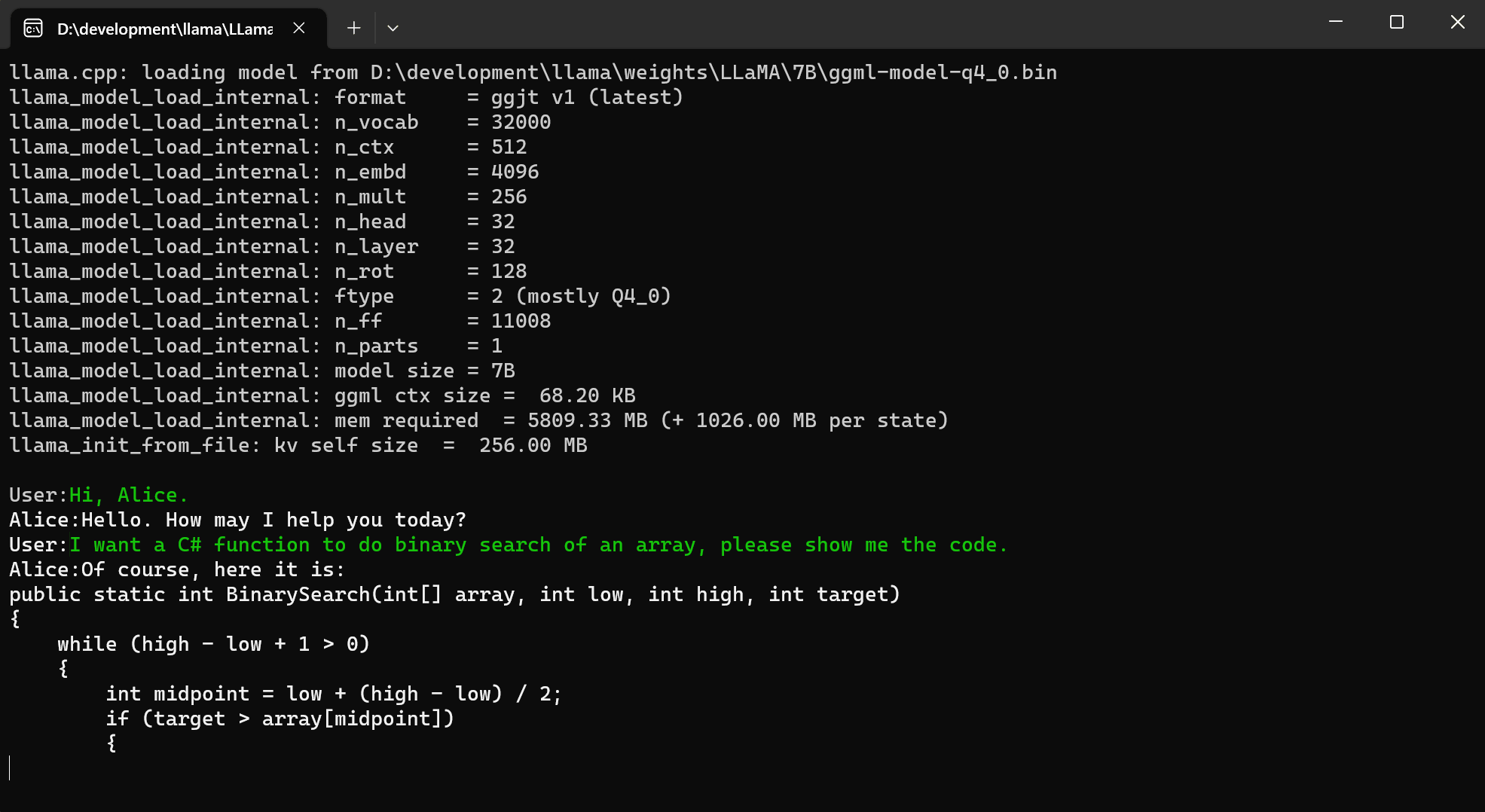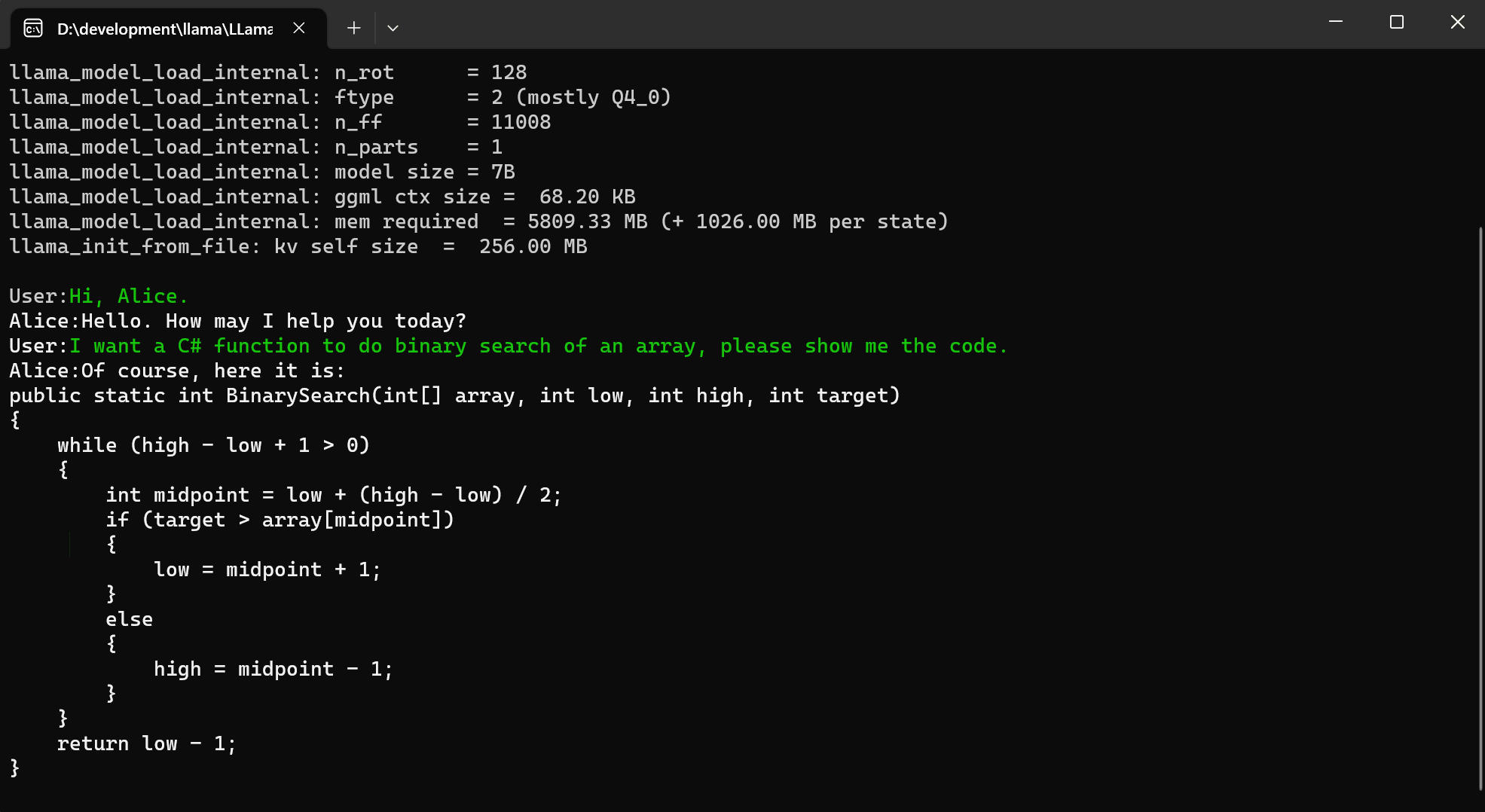
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47 | using LLama.Common;
using LLama;
string modelPath = @"<Your Model Path>"; // change it to your own model path.
var parameters = new ModelParams(modelPath)
{
ContextSize = 1024, // The longest length of chat as memory.
GpuLayerCount = 5 // How many layers to offload to GPU. Please adjust it according to your GPU memory.
};
using var model = LLamaWeights.LoadFromFile(parameters);
using var context = model.CreateContext(parameters);
var executor = new InteractiveExecutor(context);
// Add chat histories as prompt to tell AI how to act.
var chatHistory = new ChatHistory();
chatHistory.AddMessage(AuthorRole.System, "Transcript of a dialog, where the User interacts with an Assistant named Bob. Bob is helpful, kind, honest, good at writing, and never fails to answer the User's requests immediately and with precision.");
chatHistory.AddMessage(AuthorRole.User, "Hello, Bob.");
chatHistory.AddMessage(AuthorRole.Assistant, "Hello. How may I help you today?");
ChatSession session = new(executor, chatHistory);
InferenceParams inferenceParams = new InferenceParams()
{
MaxTokens = 256, // No more than 256 tokens should appear in answer. Remove it if antiprompt is enough for control.
AntiPrompts = new List<string> { "User:" } // Stop generation once antiprompts appear.
};
Console.ForegroundColor = ConsoleColor.Yellow;
Console.Write("The chat session has started.\nUser: ");
Console.ForegroundColor = ConsoleColor.Green;
string userInput = Console.ReadLine() ?? "";
while (userInput != "exit")
{
await foreach ( // Generate the response streamingly.
var text
in session.ChatAsync(
new ChatHistory.Message(AuthorRole.User, userInput),
inferenceParams))
{
Console.ForegroundColor = ConsoleColor.White;
Console.Write(text);
}
Console.ForegroundColor = ConsoleColor.Green;
userInput = Console.ReadLine() ?? "";
}
|
Examples of chatting with LLaVA
This example shows chatting with LLaVA to ask it to describe the picture.
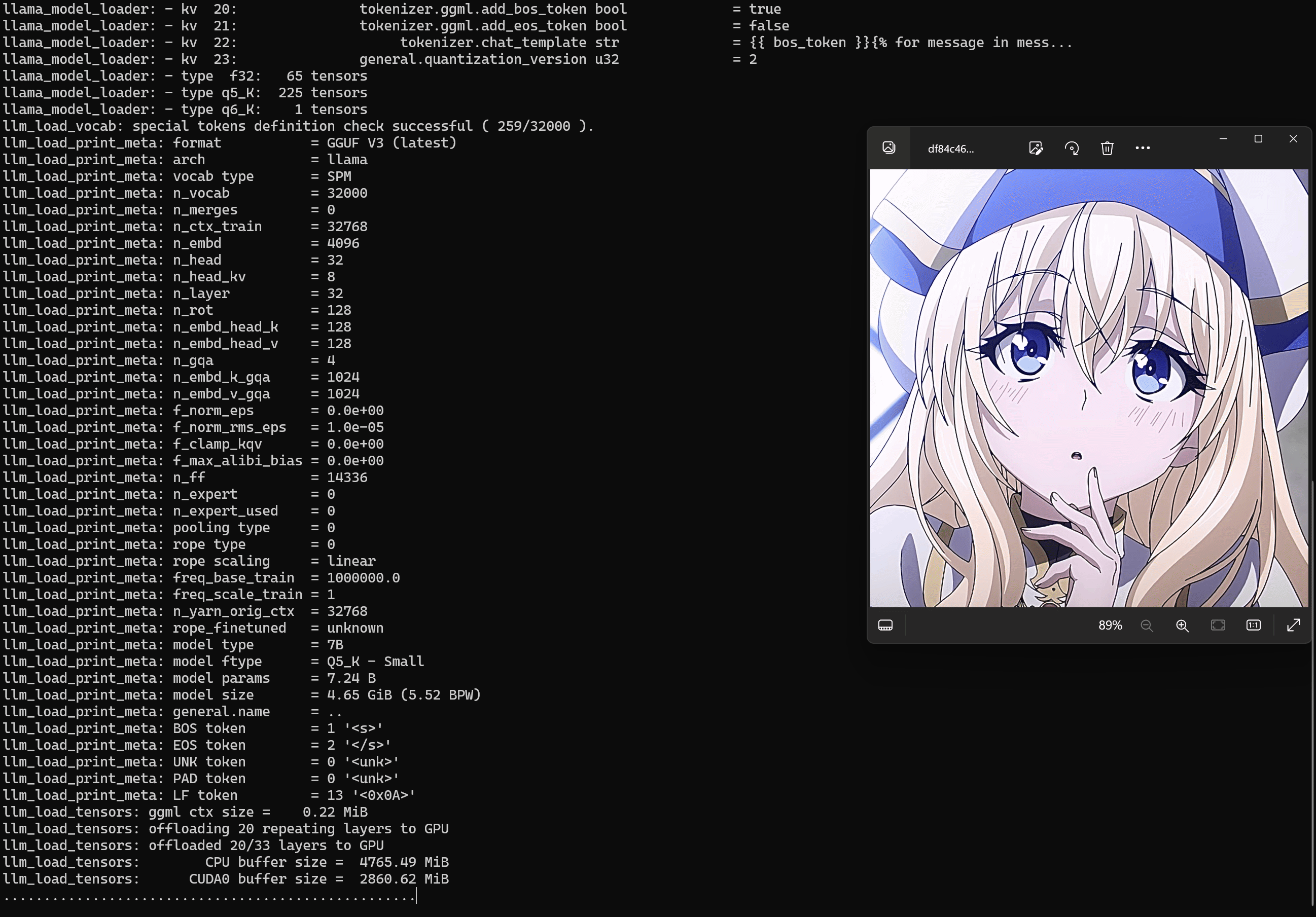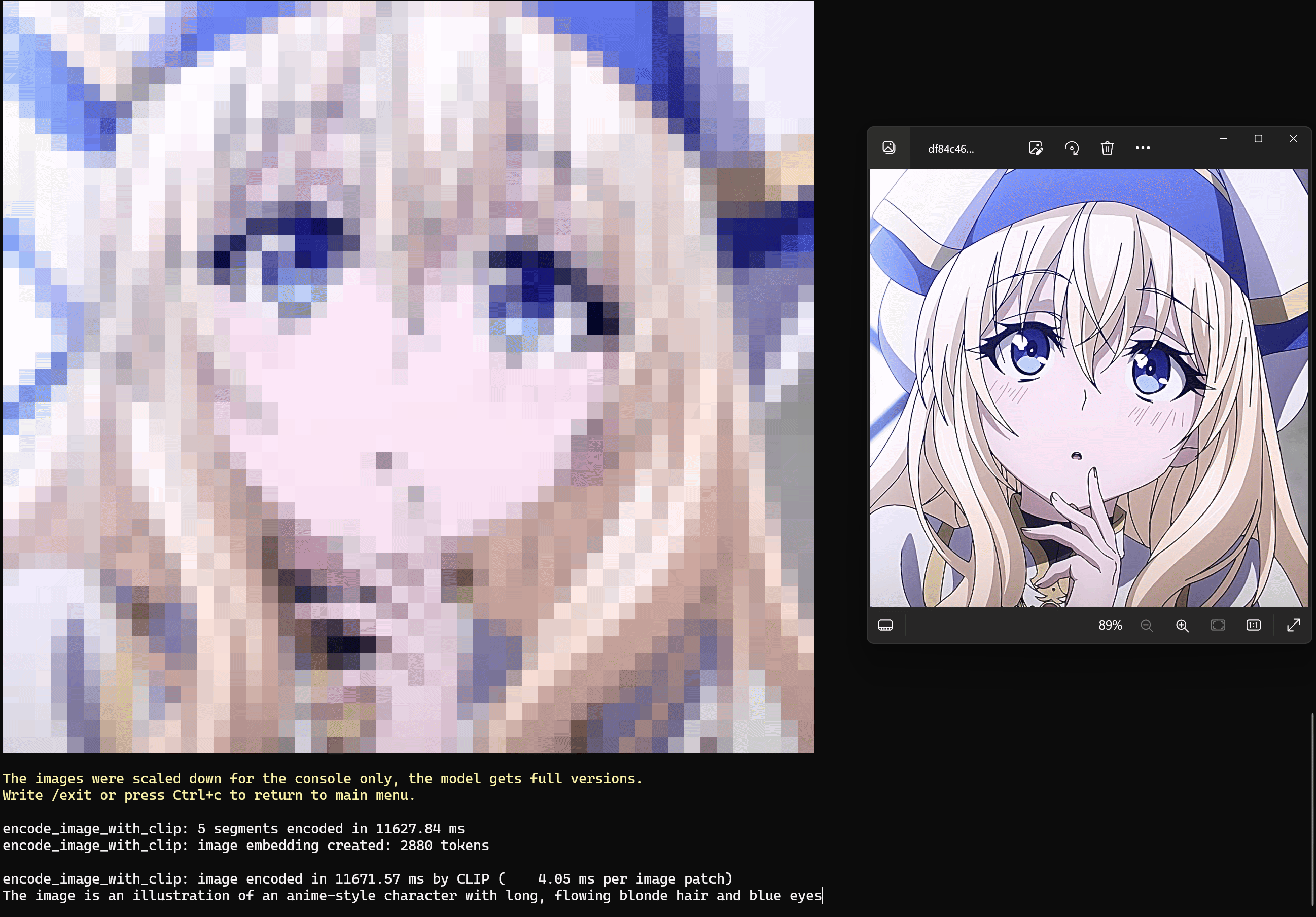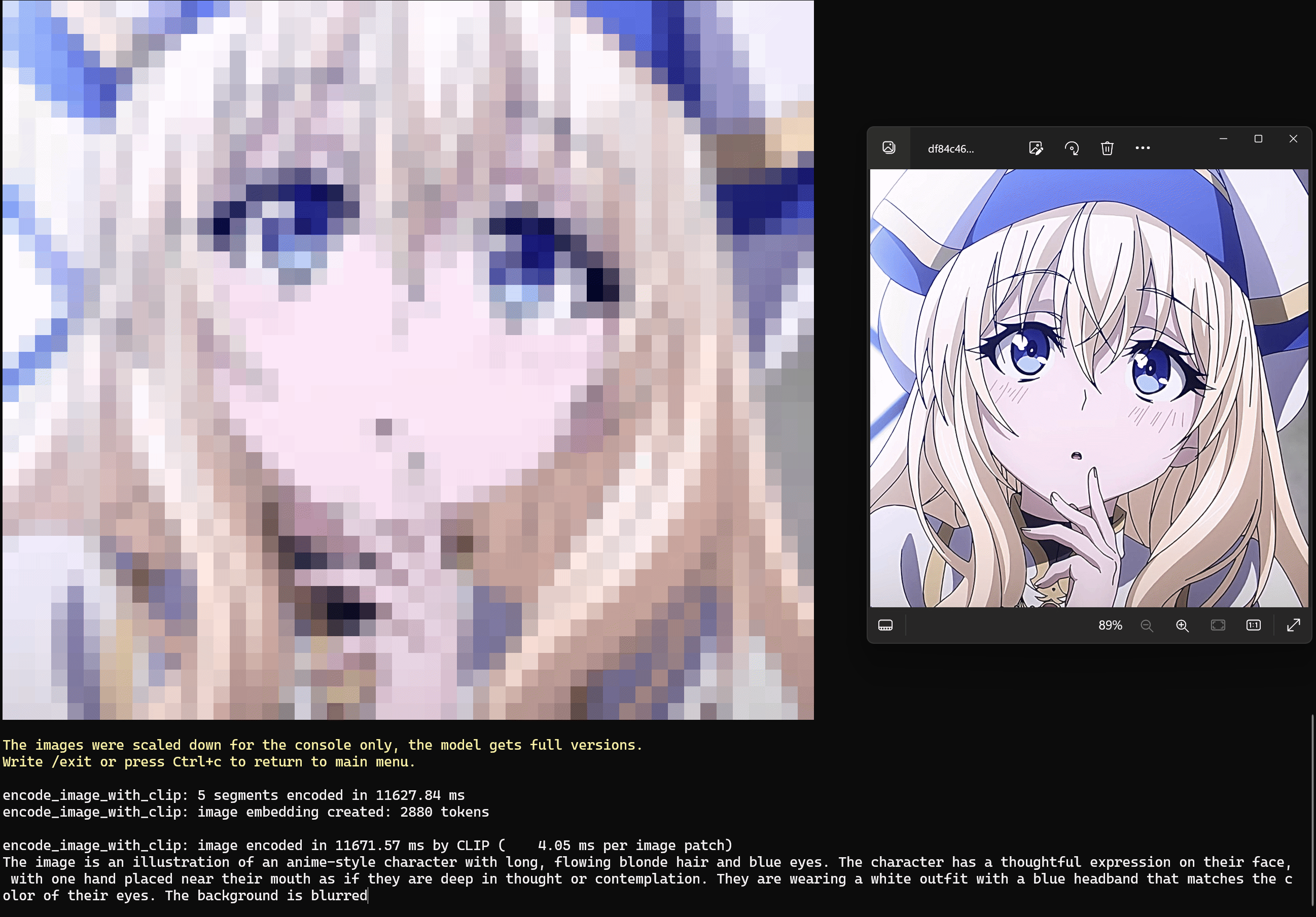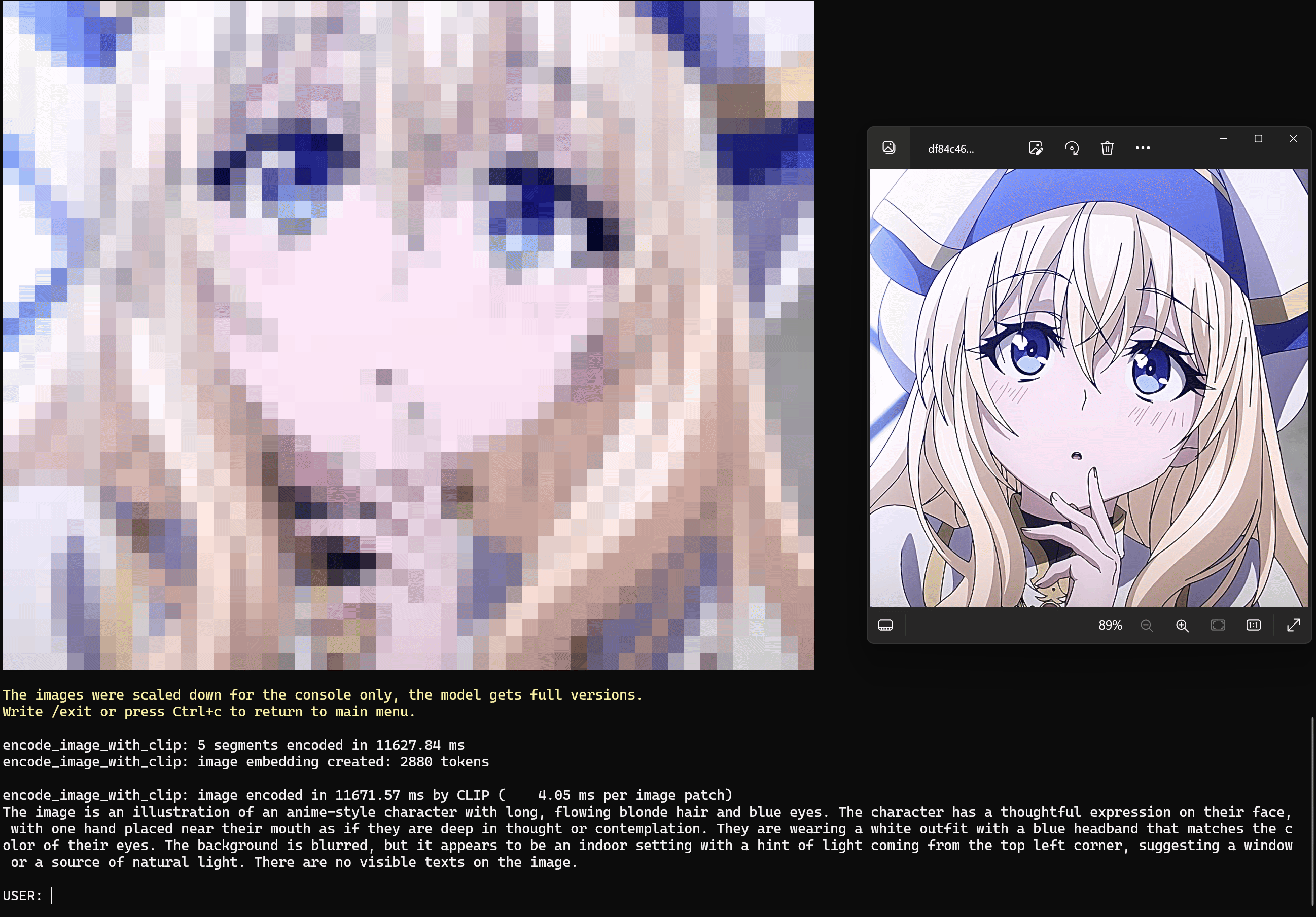
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95 | using System.Text.RegularExpressions;
using LLama;
using LLama.Common;
string multiModalProj = @"<Your multi-modal proj file path>";
string modelPath = @"<Your LLaVA model file path>";
string modelImage = @"<Your image path>";
const int maxTokens = 1024; // The max tokens that could be generated.
var prompt = $"{{{modelImage}}}\nUSER:\nProvide a full description of the image.\nASSISTANT:\n";
var parameters = new ModelParams(modelPath)
{
ContextSize = 4096,
Seed = 1337,
};
using var model = LLamaWeights.LoadFromFile(parameters);
using var context = model.CreateContext(parameters);
// Llava Init
using var clipModel = LLavaWeights.LoadFromFile(multiModalProj);
var ex = new InteractiveExecutor(context, clipModel);
Console.ForegroundColor = ConsoleColor.Yellow;
Console.WriteLine("The executor has been enabled. In this example, the prompt is printed, the maximum tokens is set to {0} and the context size is {1}.", maxTokens, parameters.ContextSize);
Console.WriteLine("To send an image, enter its filename in curly braces, like this {c:/image.jpg}.");
var inferenceParams = new InferenceParams() { Temperature = 0.1f, AntiPrompts = new List<string> { "\nUSER:" }, MaxTokens = maxTokens };
do
{
// Evaluate if we have images
//
var imageMatches = Regex.Matches(prompt, "{([^}]*)}").Select(m => m.Value);
var imageCount = imageMatches.Count();
var hasImages = imageCount > 0;
byte[][] imageBytes = null;
if (hasImages)
{
var imagePathsWithCurlyBraces = Regex.Matches(prompt, "{([^}]*)}").Select(m => m.Value);
var imagePaths = Regex.Matches(prompt, "{([^}]*)}").Select(m => m.Groups[1].Value);
try
{
imageBytes = imagePaths.Select(File.ReadAllBytes).ToArray();
}
catch (IOException exception)
{
Console.ForegroundColor = ConsoleColor.Red;
Console.Write(
$"Could not load your {(imageCount == 1 ? "image" : "images")}:");
Console.Write($"{exception.Message}");
Console.ForegroundColor = ConsoleColor.Yellow;
Console.WriteLine("Please try again.");
break;
}
int index = 0;
foreach (var path in imagePathsWithCurlyBraces)
{
// First image replace to tag <image, the rest of the images delete the tag
if (index++ == 0)
prompt = prompt.Replace(path, "<image>");
else
prompt = prompt.Replace(path, "");
}
Console.WriteLine();
// Initialize Images in executor
//
ex.ImagePaths = imagePaths.ToList();
}
Console.ForegroundColor = ConsoleColor.White;
await foreach (var text in ex.InferAsync(prompt, inferenceParams))
{
Console.Write(text);
}
Console.Write(" ");
Console.ForegroundColor = ConsoleColor.Green;
prompt = Console.ReadLine();
Console.WriteLine();
// let the user finish with exit
//
if (prompt.Equals("/exit", StringComparison.OrdinalIgnoreCase))
break;
}
while (true);
|
For more examples, please refer to LLamaSharp.Examples.